Now for a technical article.
How can several parallel programs maintain a consistent view of state. By this I mean how can two programs, possibly in different countries, manipulate common state variables in a consistent manner? How can they do so in a way that does not involve any locking?
How do transaction memories work?
To start with I must explain why concurrent updates to data represents a problem.
The conventional way to solve this problem is to lock the server while the individual transactions are taking place, but this approach is thwart with problems as I have pointed out in an earlier article.
To allow these updates to proceed in parallel and without recourse to locking, we can make use of a so called transaction memory.

Transaction Memory
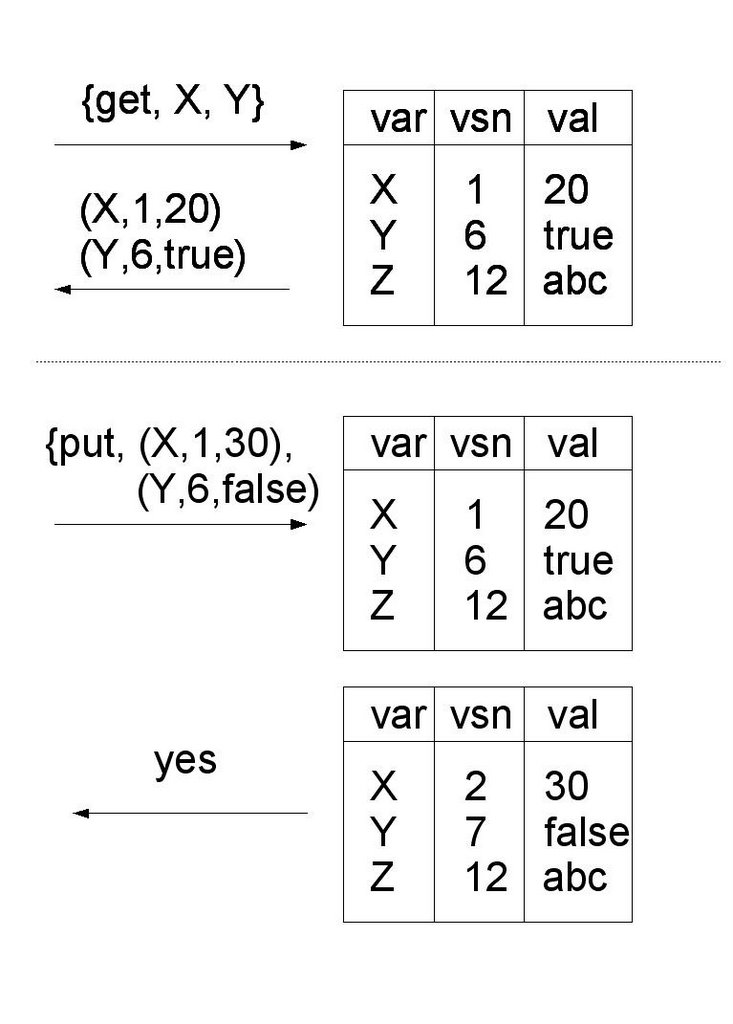
A transaction memory is a set of tuples (Var,Version,Value). In the diagram X has version 1 and value 20. Y has version 6 and value true.
The version number represents the number of times the variable has changed.
Now let's try and do a transaction. Suppose we want to change X and Y. First we send a {get,X,Y} message to the server. It responds with the values of the variables and their version numbers.
Having changed the variables we send a {put,(X,1,30),(Y,6,true)} message back to the server. The server will accept this message only if the version numbers of all the variables agree. If this is the case then the server accepts the changes and replies yes. If any of the version numbers disagree, then it replies no.
Clearly if a second process manages to update the memory before the first process has replied then the version numbers will not agree and the update will fail.
Note that this algorithm does not lock the data and works well in a distributed environment where the clients and servers are on physically different machines which unknown propagation delays.
Isn't this just the good old test-and-set operation generalised over sets?
Yes - of course it is. If you think back to how mutexes were implemented they made use of semaphores. Semaphores were implemented by an atomic test-and-set instruction. A semaphore can only have the value zero or one. The test-and-set operation said if the value of this variable is zero then change it to one this operation was performed atomically. To reserve a critical region it was protected by a flag. If the flag was zero then it could be reserved, if the flag was one then it was being used. To avoid two processes simultaneously reserving the region test-and-set must be atomic. Transaction memories merely generalise this method.
Now let's implement this in Erlang:
The answer is surprisingly simple and incredibly beautiful and makes use of something called a transaction memory.
How do transaction memories work?
To start with I must explain why concurrent updates to data represents a problem.
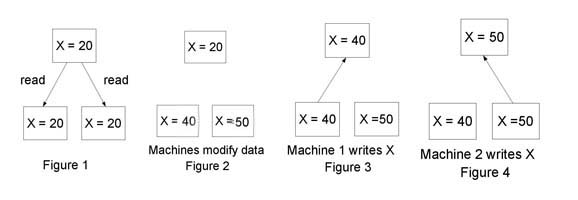
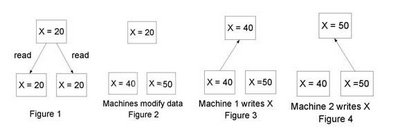
Imagine a server S with some state variable X and two clients C1 and C2. The clients fetch the data from the server (figure 1). Now both clients think that X=20. C1 increases X by 20 and C2 increases X by 30. They modify their local copies, (figures 2) and write the data back to the server (figures 2 and 3). If these updates had been performed one after the other then the final value of X stored on the server would have been 70 and not 50 obviously something has gone wrong.
The conventional way to solve this problem is to lock the server while the individual transactions are taking place, but this approach is thwart with problems as I have pointed out in an earlier article.
To allow these updates to proceed in parallel and without recourse to locking, we can make use of a so called transaction memory.
Transaction Memory
A transaction memory is a set of tuples (Var,Version,Value). In the diagram X has version 1 and value 20. Y has version 6 and value true.
The version number represents the number of times the variable has changed.
Now let's try and do a transaction. Suppose we want to change X and Y. First we send a {get,X,Y} message to the server. It responds with the values of the variables and their version numbers.
Having changed the variables we send a {put,(X,1,30),(Y,6,true)} message back to the server. The server will accept this message only if the version numbers of all the variables agree. If this is the case then the server accepts the changes and replies yes. If any of the version numbers disagree, then it replies no.
Clearly if a second process manages to update the memory before the first process has replied then the version numbers will not agree and the update will fail.
Note that this algorithm does not lock the data and works well in a distributed environment where the clients and servers are on physically different machines which unknown propagation delays.
Isn't this just the good old test-and-set operation generalised over sets?
Yes - of course it is. If you think back to how mutexes were implemented they made use of semaphores. Semaphores were implemented by an atomic test-and-set instruction. A semaphore can only have the value zero or one. The test-and-set operation said if the value of this variable is zero then change it to one this operation was performed atomically. To reserve a critical region it was protected by a flag. If the flag was zero then it could be reserved, if the flag was one then it was being used. To avoid two processes simultaneously reserving the region test-and-set must be atomic. Transaction memories merely generalise this method.
Now let's implement this in Erlang:
-module(tm).
-export([new/0, addVar/2, getVars/2, putVars/2]).
%% new() -> Pid
%% create a new transaction memory (TM)
%%
%% addVar(Pid, Var) -> ok
%% add a variable to the TM store
%%
%% getVars([V1,...]) -> [{Vsn,Data},....]
%% lookup variables v1,V2, ... in the TM
%%
%% putVars([{Var,Vsn,Data}]) -> Bool
%% update variables in TM
%% Heres a sample run
%%
%% 1> c(tm).
%% {ok,tm}
%% 2> P=tm:new().
%% <0.47.0>
%% 3> tm:addVar(x).
%% ok
%% 4> tm:addVar(P,x).
%% ok
%% 5> tm:addVar(P,y).
%% ok
%% 6> tm:getVars(P, [x,y]).
%% [{ok,{0,void}},{ok,{0,void}}]
%% 7> tm:putVars(P, [{x,0,12},{y,0,true}]).
%% yes
%% 8> tm:putVars(P, [{x,1,25}]).
%% yes
%% 9> tm:getVars(P, [x,y]).
%% [{ok,{2,25}},{ok,{1,true}}]
%% 10> tm:putVars(P, [{x,1,15}]).
%% no
new() -> spawn(fun() -> loop(dict:new()) end).
addVar(Pid, Var) -> rpc(Pid, {create, Var}).
getVars(Pid, Vgs) -> rpc(Pid, {get, Vgs}).
putVars(Pid, New) -> rpc(Pid, {put, New}).
%% internal
%%
%% remote procedure call
rpc(Pid, Q) ->
Pid ! {self(), Q},
receive
{Pid, Reply} -> Reply
end.
loop(Dict) ->
receive
{From, {get, Vars}} ->
Vgs = lists:map(fun(I) ->
dict:find(I, Dict) end, Vars),
From ! {self(), Vgs},
loop(Dict);
{From, {put, Vgs}} ->
case update(Vgs, Dict) of
no ->
From ! {self(), no},
loop(Dict);
{yes, Dict1} ->
From ! {self(), yes},
loop(Dict1)
end;
{From, {create, Var}} ->
From ! {self(), ok},
loop(create_var(Var, Dict))
end.
update([{Var,Generation,Val}|T], D) ->
{G, _} = dict:fetch(Var, D),
case Generation of
G -> update(T, dict:store(Var, {G+1, Val}, D));
_ -> no
end;
update([], D) ->
{yes, D}.
create_var(Var, Dict) ->
case dict:find(Var, Dict) of
{ok, _} -> Dict;
error -> dict:store(Var, {0,void}, Dict)
end.
13 comments:
I think you missed out one of the biggest gains of STM over locks: STM is composable, whereas locks aren't. This very simple property, which I'm sure any programmer can understand, translates directly into modularity and therefore simple code. A finer point is that a good STM implementation's performance (using static info to optimize certain pathways) can come to within an epsilon of a hand-crafted lock-free (or even locked) data structure, but again, be exceptionally simple to use and understand.
So you are saying I have to keep retrying the operation until I get consistent sequence numbers? With a lock I can guarantee my update will succeed. There is no possibility for live lock.
Correct me if I'm wrong, but I think STM and locks are not excluding terms. In order to achieve STM you need either an atomic test-and-set operation in your runtime or a way to implement it... by using locks.
So when using STM you're implicitly using lock, just in a formal way where you ensure no starving nor mutual blocking nor any other typical concurrency error.
Maybe I missed a meeting but is it not very easy to create a scenario where one client suffers starvation? Assume S, C1 and C2.
1) C1 { get, X } -> S
2) C1 <- ( X, 1, 10 ) S
3) C2 { get, X } -> S
4) C2 <- ( X, 1, 10 ) S
5) C1 { put, X, 1, 20 } -> S
6) C1 <- ( yes ) S
7) C2 { put, X, 1, 22 } -> S
8) C2 <- ( no ) S
9) C1 { get, X } -> S
10) C1 <- ( X, 2, 20 ) S
11) C2 { get, X } -> S
12) C2 <- ( X, 2, 20 ) S
13) C1 { put, X, 2, 30 } -> S
14) C1 <- ( yes ) S
15) C2 { put, X, 3, 32 } -> S
16) C2 <- ( no ) S
... and C2 will never set it's value (as in 8) and 16) above). Even if this scenario is somewhat constructed I suppose it's quiet possible.
I have heard this referred to as "optimistic locking". What about starvation/priority-inversion? You have client A who updates the server frequently, and client B who updates the server very infrequently. It's easy to get into a situation where B's updates are never made to the server because B's version info never matches because A is always changing it.
You mention that this algorithm works well where there are unknown propagation delays. This will normally be true, but you can run into the same starvation issue simply due to the delay, if one machine is always slower to post updates than the other(s).
One solution is to have a second algorithm responsible for monitoring success/failure of updates and selectively choosing updates from clients that have failed "too much" over those that have succeeded "too much". This works because of the fundamental transactional memory behavior--the "too successful" clients will have their transactions thrown away (and thus needing to retry) so the "too unsuccessful" client can finally post its update.
This method is used by the Firebird
database engine. Every interaction with the engine occurs within a transaction. All updates etc are marked with a transaction number. There may be multiple versions of the same record. usually only the deltas between record contents are stored. This allows older transactions to see consistent snapshots of the database by only looking at record versions with lower transaction numbers. Record locking is not required but can be done by doing a dummy update which will cause older transactions to fail on update attempts as they have lower transaction IDs. Its A good system that's why MySQL hired the creator or Firebird (open source fork of Interbase) to create a new engine.
willy thanks for your poignant observation.
Inaddition, STM avoid "general" concurrency related errors --deadlock, livelock,priority inversion...
What about user specific assertions...Rather aborting transaction whenever the version of any variable do not match as expected(because some other transaction interfered), one could abort if only a user given assertion over a subset of variables is violated.
The former approach overapproximates all properties that are violated if atomicity of current transaction is violated. However, user may only be interested in the consistency of a few variables( rather than whole memory, a chunk of memory occupied by subset of varibles logged/versionised during transaction).
Well, this would generate an advantage only if the processes are tightly coupled, leading to lot of interference among transactions.
genneth wrote:
A finer point is that a good STM implementation's performance (using static info to optimize certain pathways) can come to within an epsilon of a hand-crafted lock-free (or even locked) data structure, [...]
References? I don't know of any practical (even proposed) STM implementation that has an overhead for typical programs of less than a factor of 2. The worst-case performance is usually *much* worse.
Anonymous wrote: [...] With a lock I can guarantee my update will succeed. There is no possibility for live lock.
Most of the recent work on STM has used "optimistic concurrency control", in which any attempt to execute a transaction might have to retry. However there is nothing to stop an STM from using a more pessimistic strategy that either avoids retries completely, or limits the number of times a retry can occur for a given transaction. I believe the emphasis on optimistic strategies comes from the database world, and that typical database usage patterns make conflicts less likely than they would be if STM were used in a wider range of applications.
Willy wrote:
[...] I think STM and locks are not excluding terms.
It's important to distinguish the semantics of a language construct from its implementation. A user of a typical STM system is not programming with locks, implicitly or otherwise. (Even STM algorithms that use mutual exclusion have very different semantics from locks.) This is just the same as saying that a user of a high-level language is not programming with processor registers, branch instructions, etc., even though the implementation of the language uses these.
Comment posting doesn't appear to work with Firefox 1.5.0.7 (Javascript is enabled). I had to post this one with MSIE.
Maybe my knowledge of Erlang is not deep enough, but doesn't the described implementation of STM serialize all requests to the TM store? On multiprocessors this would be clearly a drawback in comparison to other STM implementations which allow truely parallel access to different variables in the same store.
To Stefan Plantikow:
It is easy to change the TM to one-server-per-client mode, then what you mean by "truely parallel access" lies in the database - 'dict' here. Whatsoever, the only real difference is on which layer to do the "dirty work" - reconciling resource contentions.
порно подростки просмотр онлайн http://free-3x.com/ официальный сайт курских студентов free-3x.com/ порно молоденькие онлайн [url=http://free-3x.com/]free-3x.com[/url]
[url=http://sunkomutors.net/][img]http://sunkomutors.net/img-add/euro2.jpg[/img][/url]
[b]where to buy photoshop in, [url=http://sunkomutors.net/]adobe air software[/url]
[url=http://sunkomutors.net/][/url] Pro 9 Advanced buy igo software
free serial number for adobe photoshop cs3 [url=http://sunkomutors.net/]microsoft software help[/url] student discount on computer software
[url=http://sunkomutors.net/]buy photoshop cs[/url] software prices uk
[url=http://sunkomutors.net/]future of filemaker pro[/url] software purchase price
small office software [url=http://sunkomutors.net/]office hours software[/b]
Post a Comment